

前言
一
多元的数据来源
与之不同,金融科技风控模型使用的数据源更加多元,包括弱金融属性的行为类数据,如电商App的浏览页面、页面停留时间、关注的商品种类、产品评分和投诉记录、即时通信App加入的社群种类、社交App的互动话题等。在数字时代,一个人的用户画像更多依靠其在互联网世界的行为轨迹来描绘。风控模型搭建所倚赖的数据,也从金融类数据向行为类数据扩张。
比如,在一些创新的大数据征信模型中,开始将海量数据纳入征信体系,并以多个信用模型进行多角度分析。在ZestFinance模型中,往往要用到3500个数据项,从中提取70000个变量,再利用身份验证模型、欺诈模型、还款能力模型、还款意愿模型、稳定性模型等十余个模型进行分析,每一个子模型从不同的角度分析用户的信用情况,评分结果更加全面准确。
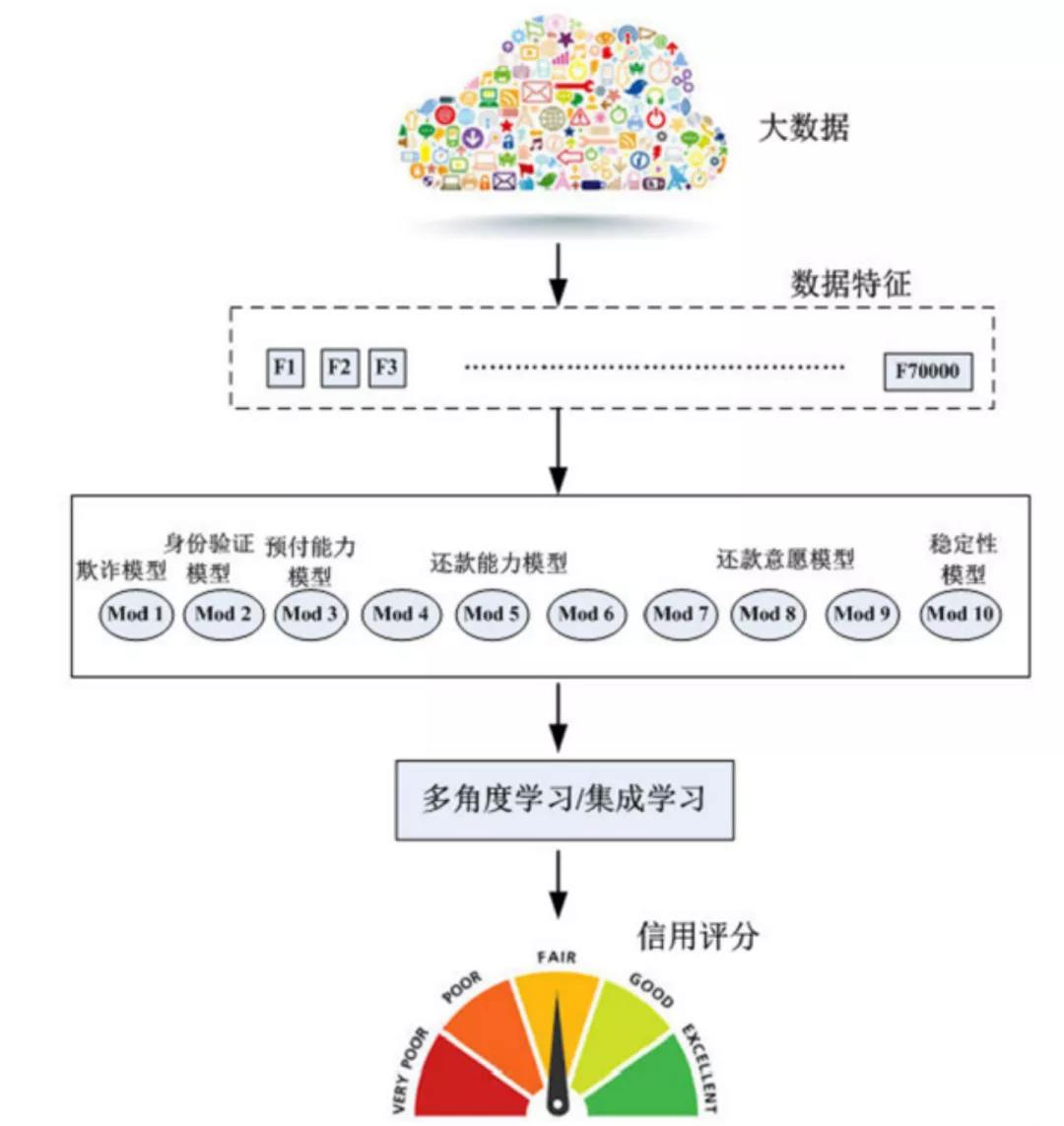
按照《信息安全技术 个人信息安全规范》的要求,如果能够关联特定个人,上述数据很可能落入敏感个人信息的范畴,不仅需要在使用数据前进行必要性论证,还要得到信息主体的单独同意。但大量数据获得信息主体的逐一同意,不经济也不现实。因而,风控模型构建所使用的训练数据,应当优先进行匿名化处理。
二
数据汇聚的重识别风险
《个人金融信息保护技术规范》对此也有所提示,在个人金融信息的加工处理过程中,“应对匿名化或去标识化处理的数据集或其他数据集汇聚后重新识别出个人金融信息主体的风险进行识别和评价,并对数据集采取相应的保护措施”。
因此,如果风控模型与个人权益密切相关,或涉及多维、大量的脱敏信息,企业在搭建风控模型前,最好进行用户信息保护影响评估。评估的内容包括融合的数据类型与级别、具体融合操作、再次识别特定个人的可能性、是否具备相应的补救措施等。
三
模型逻辑的可解释性
于此,当金融机构利用风控模型决定是否为用户提供服务时,比如判断顾客信用状况以决定是否放贷,应当将风控模型作为准确性增强工具,而非唯一决策机制。实务中,在获得模型评估结果后,应另设人工复核或交叉验证路径,避免因单个模型的独断分析而导致错误评估。
另外,鉴于用户有权要求信息处理者说明自动化决策方式,机构有必要在应用风控模型之前,确定模型内在逻辑的可解释性,履行必要的内部测试、压力测试和评估程序,确保评价规则可解释、训练数据可追溯,能够以清楚方式向用户释明模型逻辑。实务中,机构可以简要说明模型的函数逻辑,并介绍统计数据的类别和分析维度,如位置移动数据会影响工作分和稳定分、App行为数据则影响兴趣分和文化分。
四
用户金融信息“授权同意”
建立风控模型后,模型应用是“信息导入-结果输出”的线性流程。在个人信息保护强监管的背景下,获得用户对模型应用的授权同意是前置程序。
金融机构通常会部署多个应用系统,经过日积月累的数字化运营,这些系统沉淀的数据规模也较为庞大。以银行业为例,波士顿咨询的调研表示,银行业每创收100万美元,平均就会产生820GB的数据。个人账户、交易信息、历史借贷信息等用户金融信息都是风控模型的对口数据。
但内部系统自带的用户金融信息也不能随意用于风控模型,获得用户的授权同意是合规基础。如果应用于风控模型不属于用户金融信息收集时所声明的使用范围,金融机构有必要再次征得信息主体的明示同意。而这一点,在实务中往往是企业所忽视的。
授权同意的方式有必要“醒目”一些。《商业银行互联网贷款管理暂行办法》的规定,对于借款人风险数据,即贷款风险识别、分析、评价、监测、预警和处置等环节收集、使用的各类内外部数据,商业银行需要在数据授权申请时,在线上相关页面醒目位置提示借款人详细阅读授权书内容,并在授权书醒目位置披露授权风险数据内容和期限,确保借款人完成授权书阅读后签署同意。
五
信息主体的行权保障
考虑到金融风控模型对用户权益的影响显著,金融机构有责任保证数据及模型质量,并保障用户的信息主体权益。
具体而言,机构应向用户披露接受查询、投诉申请的渠道或联系方式,及时响应个人及企业用户的查询请求、异议申请或投诉意见。
当用户认为应用于风控模型的信息内容存在错误或遗漏的,或对风控模型决策结果存有疑义,可以通过顾问、客服或其他联系渠道提出异议,机构应及时响应诉求,解释风控决策的理由并告知异议处理结果。在用户授权同意风控模型的应用时,企业还要明确提示用户注意,风控模型所适用的机器学习机制存在固有风险,对用户权益存在直接影响。与此同时,机构也有必要通过风控模型的回测、验证机制,不断检验历史风控模型的准确度、升级完善模型逻辑。
总结
当下数字经济蓬勃发展,企业构建适合数字时代发展的合规体系日益重要。对于金融科技行业而言,风控无边,而合规有界。在利用风控模型降低金融风险的同时,机构也要从模型搭建到模型应用,谨防数据违规风险。
END
声明:本微信文章仅为交流探讨之目的,不得视为广悦数据合规研究院或其律师出具的正式法律意见,任何仅依照本文的全部或部分内容而做出的行为及因此带来的后果均由行为人自行负责。如果您需要法律意见或有意就相关议题进一步交流,可以通过电子邮件与我们联系,E-mail:hlw@wjngh.cn 。

